Reference:
- «深入理解 Java 虚拟机» 周志明著
- « JVM Specification Java SE 1.8 »
作为一名 Java 程序员,相信大家都知道,我们写的 Java 源码会被编译成 .class 文件然后被 JVM 加载运行。为了深入地学习 JVM 我们很有必要知道 .class 文件的结构,它们是怎么被加载进入 JVM,以及如何被 JVM 解析的。
先看一个例子,假设我们有如下的源码:
public class Example {
private int m;
public int inc() {
return m + 1;
}
public static void main(String[] args) {
System.out.println("hello world");
}
}
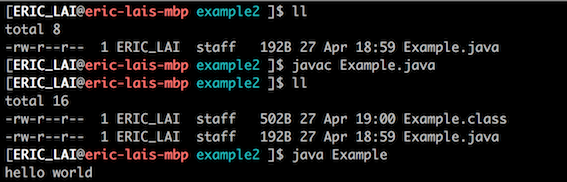
打开命令行,编译并且运行一下这个例子的源码:
这么看,并没有什么特别的,仅仅是一个最最最简单的 “hello world” 程序。但是这次我们的关注点不放在这段程序运行的结果上,我们的关注点而是我们使用 javac 命令编译源码后产生的 Example.class 文件。
Example.class 文件里面包含的就是我们所说的“字节码(byte code)”,让我们打开这个文件看看,由于是字节码,我们要使用能够识别 hex 的工具打开:
// open with vim
vim Example.class
// inside vim type
: % ! xxd
// want to go back
: % ! xxd -r
当你输入 vim Example.class 的时候,你应该会看到一堆乱码, 然后当你输入 : % ! xxd 之后,你应该能够看到像下面图片一样的内容:
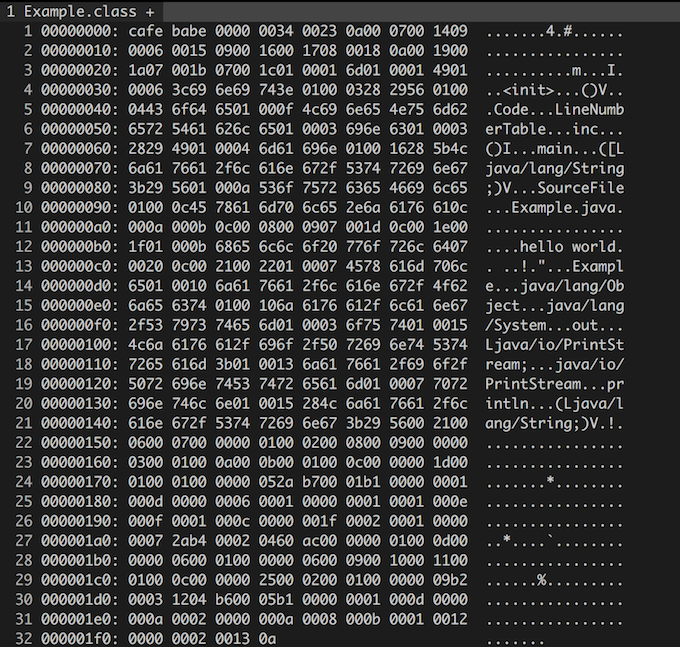
一个小小的 “hello world” 程序的字节码就像上面显示的一样(看起来好复杂啊 :< ),不用方!下面我们将详细的来解释一下这个字节码文件的结构是怎样的。
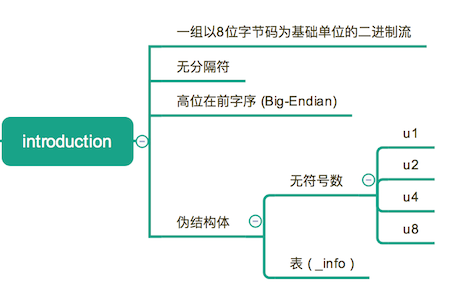
Class 文件是一组以 8 位字节码为基础单位的二进制流,各个数据项目严格按照规定的顺序紧凑地排列在 Class 文件中,中间没有任何分隔符。当遇到需要占用 8 位以上的空间时,按照高位在前的方式分割成若干个 8 位字节进行存储。
Java 虚拟机规范规定,Class 文件采用一种伪结构体来存储数据,这种伪结构体里只有两种数据类型:
下图显示了一个完整的 Class 文件的结构,后文将逐一介绍这几个部分。
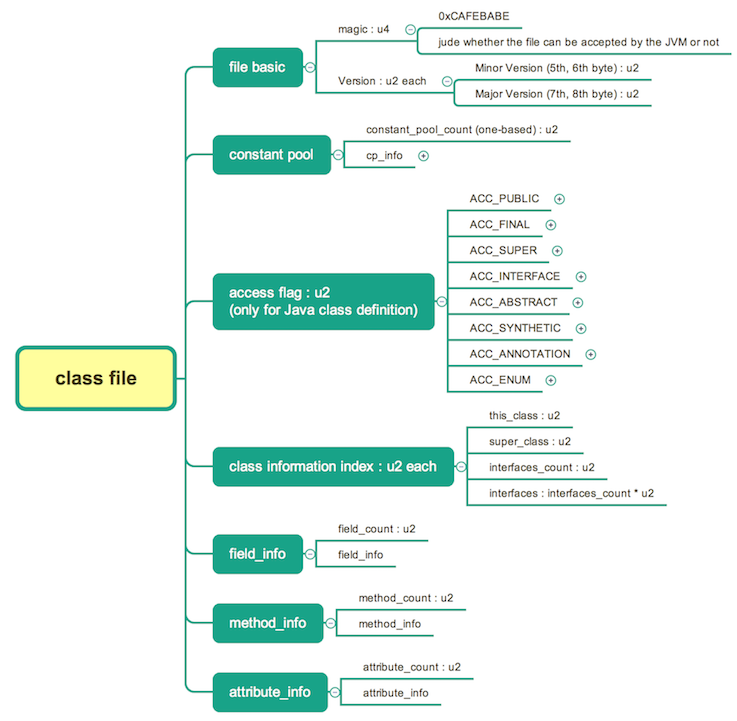
Class 文件中的所有数据都是按照严格规定的顺序进行排列的,“魔数” 就是文件中出现的第一个数据项。所有由 javac 命令编译生成的 .calss 文件前四个字节都是一样的,称为“魔数 (magic number)”,内容为 CAFEBABE。
Class 文件的版本号分为两个部分:
Minor Version,第 5 和 第 6 字节;Major Version,第 7 和 第 8 字节;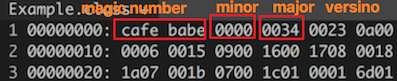
上图 major version 中的 34 是十六进制,它代表十进制中的 52,下表为 Java Version 和 Major Version 的对照表,可以看到 52 对应的是 Java 8。

下面的是我机器上的 Java 版本,可以看到是 Java 1.8.0_51 和上面的结果符合。

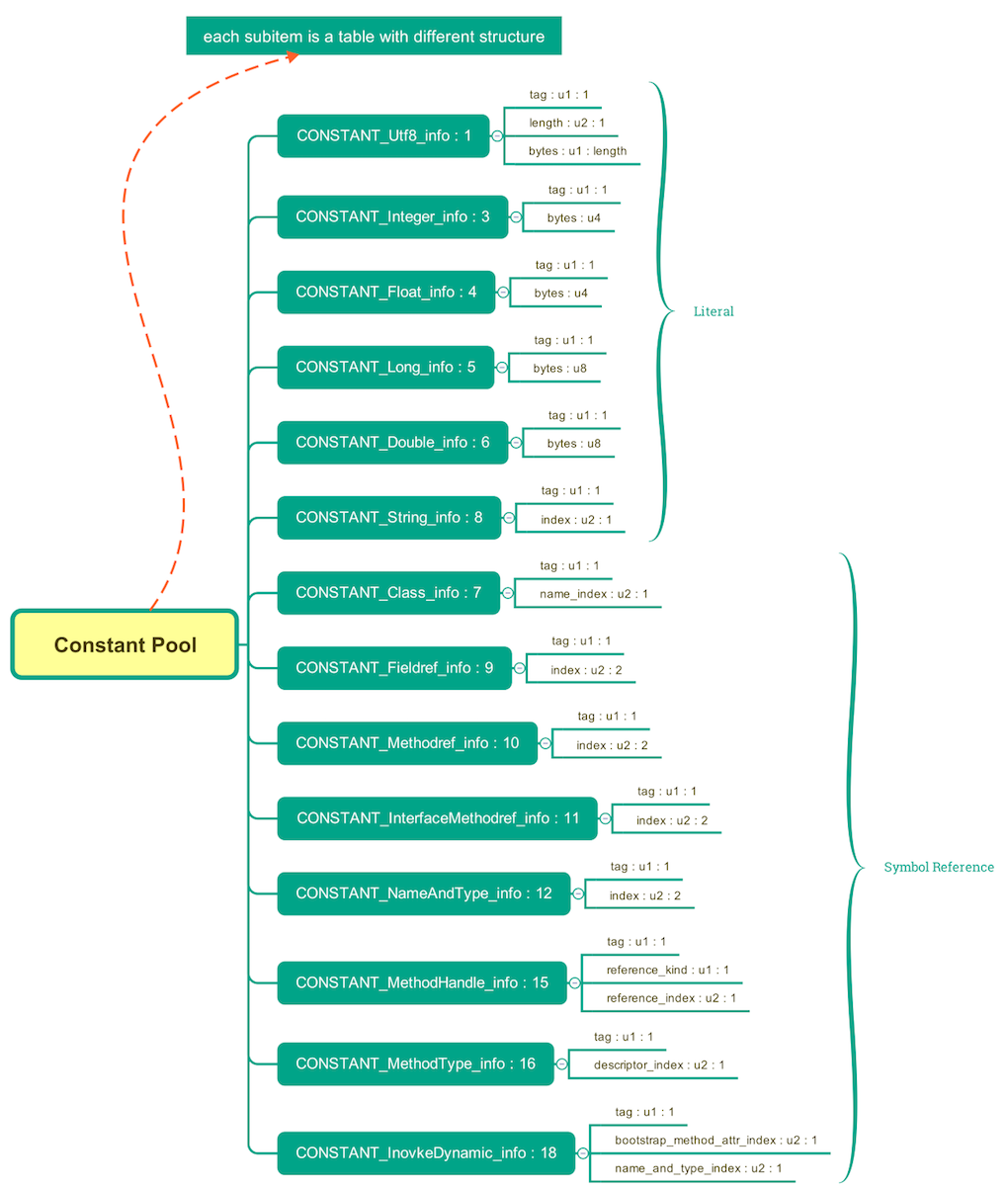
常量池 (constant pool) 是 Class 文件里比较复杂的一个数据项。顾名思义,常量池是一个用来堆放常量的地方,和 “线程池” 的概念基本“类”同。由于每个程序里面需要的常量数目都相同,所以常量池的长度也是不确定的。所以,我们需要一个 length 变量来指示当前常量池的大小,这个变量的名字叫做 “常量池计数器 (constant_pool_count)”。值得一提的是,这个计数器是从 1 开始计数的(0 保留下来做别的用处了),不像计算机科学里的大多数计数器从零开始,这也是 Class 文件里唯一一个特例。
接着 “常量池计数器” 后面就是 “常量表(cp_info)” 了,这个表里的每一个子项 (entry) 都是一个表。每一个子项都必定是已经规定好的 14 个,下图列出了这 14 种可能性,以及每个字表的结构 (这 14 个字表的结构都不一样)。
常量池中主要放置两种类型的常量:
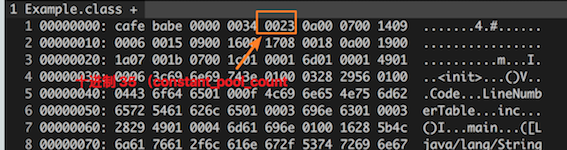
下面,我们尝试着分析一下我们一开始的例子里面的常量池数据。从下图中我们可以看到,计数器的数值转化成十进制后是 35。这表明一共有 34 项常量 1 ~ 34,零保留下来了,表示 “不引用常量池的任何一个项目”。
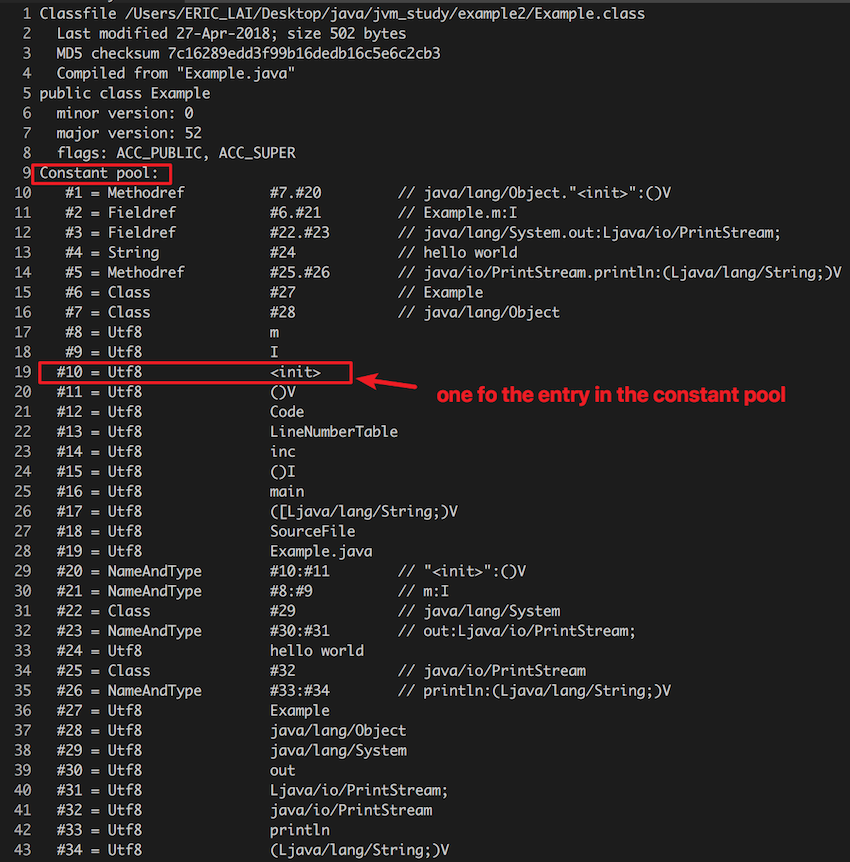
紧接着计数器的是一个 tag 0x0a -> 10 (十进制),查上表,可以知道这是一个 CONSTANT_Methodref_info 类型的表 (符号引用)。再仔细看表 CONSTANT_Methodref_info 由三个子项组成,分别是 tag (u1 类型),index(u2 类型,指向方法属于的类),index(u2 类型,指向方法的名称)。按照数据类型,截取相应的数据:
查表可以知道,这个方法引用符指向的是 java/lang/Object."<init>":()V。乍一看我们可以想象到,这个东西 “像” 是 Object 类的构造方法。其实 Java 为我们提供了一个字节码分析工具,我们可以输入如下命令:
javap -verbose Example
可以看到输入如下 (和我们分析的吻合):
后文不再逐一分析常量池的内容,有需要可以自行验证多几项。总而言之,常量池里的内容如果是字面量就可以被别的表引用,如果是符号引用则会继续引用别的表。多一句嘴,这写符号引用会在某个阶段被替换成内存中的地址,在传统的编译型语言中 (比如 C/C++),这一步骤被称为 “链接 (linking)”。
紧接着常量池之后的内容是访问标志(上图途中,出现在常量池上方)。注意,这里说的是类级别的访问标志。就像它的名字一样,这是一个 flag,要么有要么没有,可以取以下的值,一个类可以有多个标志。
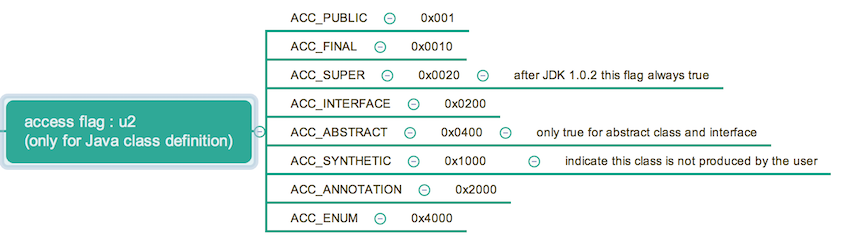
同样看一下我们的例子,上面使用 javap 的分析已经知道了标志为 ACC_PUBLIC, ACC_SUPER,我们来验证一下。首先看源码,这仅仅是一个普通类,不是接口也没有被声明为抽象。由于使用的 JDK 版本为 1.8,所以 ACC_PUBLIC, ACC_SUPER应该为真,进行计算 -> 0x0001 | 0x0020 = 0x0021 可以知道 access_flag 的值应为 0x21。
访问标志结束之后,是当前类信息的 3 个集合:类索引 (this_class,u2类型),父索引 (super_class,u2类型),接口索引 (interfaces,u2类型集合)。
看上图,我们例子中,这三个集合的信息如下:
很显然,符合我们的源码。
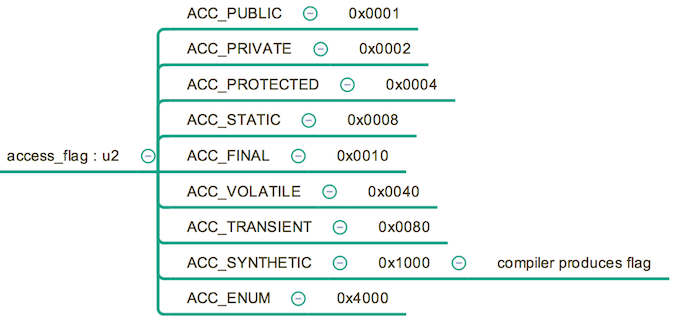
字段表,顾名思义了,用来描述类字段 (field) 的表,包括类变量和实例变量。在 Java 中,一个字段可以有什么来描述呢? 访问修饰符,类变量(static)还是实例变量,是否 final, volatile, transient 修饰,字段类型,字段名称。前面的 “修饰” 几项,要么被某个关键字修饰,要么不被修饰,可以用 flag 来表示,字段类型和名称是不确定的不能使用标志,需要引用常量池的数据项来表示。
字段表的格式如下:
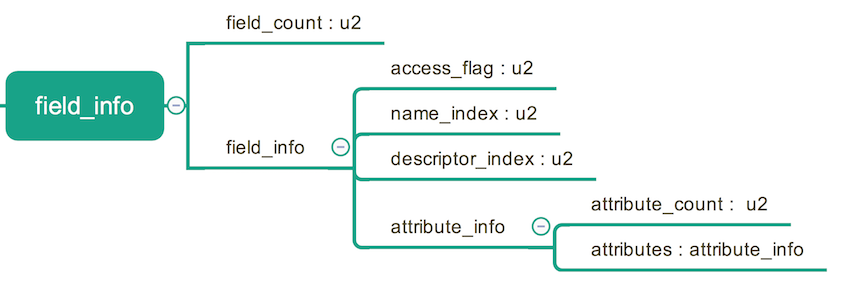
在这里,访问表示的处理和类的访问标志的处理方法基本相同,只是描述字段的访问标志的项目与描述类的有所不同,后文会给出具体的描述表。name_index, descriptor_index 的作用是指向常量池的具体条目。属性表会在后文叙述,它主要存储一些额外信息,比如如果一个String类型的字段被 static修饰,可能字段表里会有一个条目指向常量池的常量来表示这个字段的值。
如果你仔细的在 javap 命令给出的分析结果中查看,会发现一些奇奇怪怪的符号,如下所示。这些 I, V究竟表示的是什么意思呢?这就是我们上问提及的 descriptor的一部分,原来对于类型,Class 文件中用一个字符来表示标识。I 表示整形, V 表示 void。

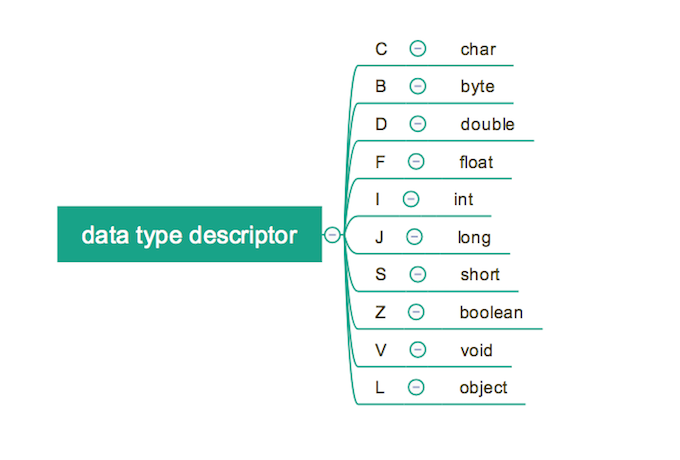
上面没有提到的还有数组字段,数组字段在类型的基础上会添加一个前缀 [,这个前缀的个数取决于数组的维度,比如二维数组那就会是 [[。
方法表集合,用来描述类中定义的方法。和字段差不多,只是访问表示略有不同,并且方法表会在其属性表中多些其他的子项,比如,方法返回值类型,参数列表,方法内部的局部变量等。具体见下图:
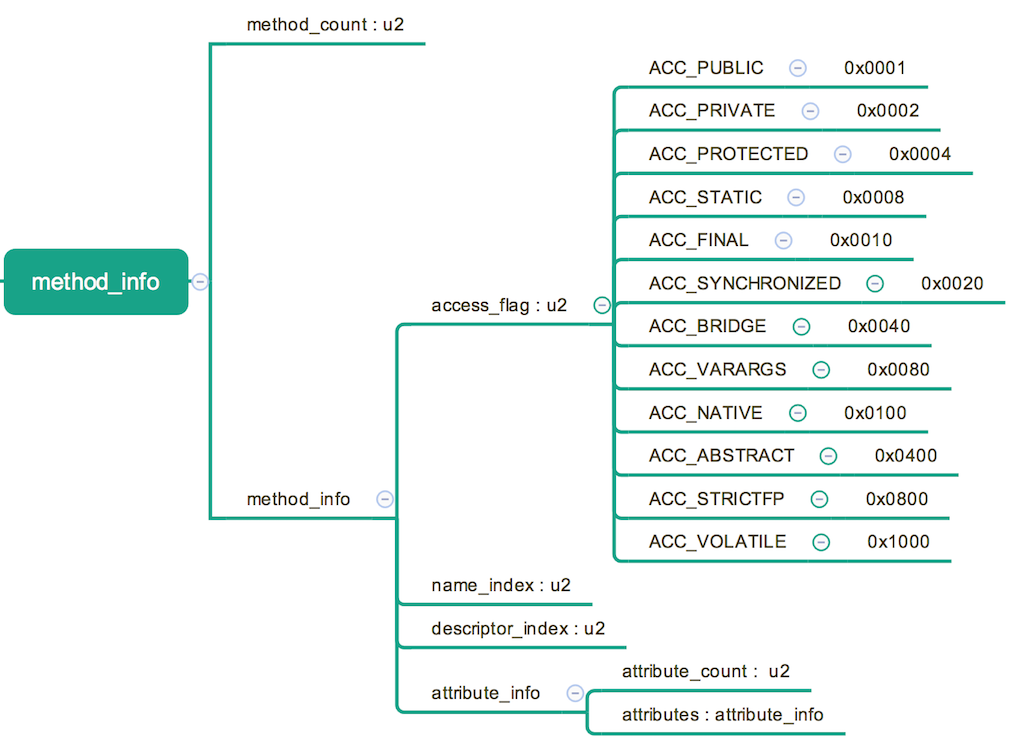
这里如果写过 compiler 的同学就会觉得很奇怪了,方法里的代码到哪里去了? 所有方法里的代码会被编译成指令放在属性表的 code 属性里面。相关的内容,说到字节码执行引擎的时候会详细的叙述。
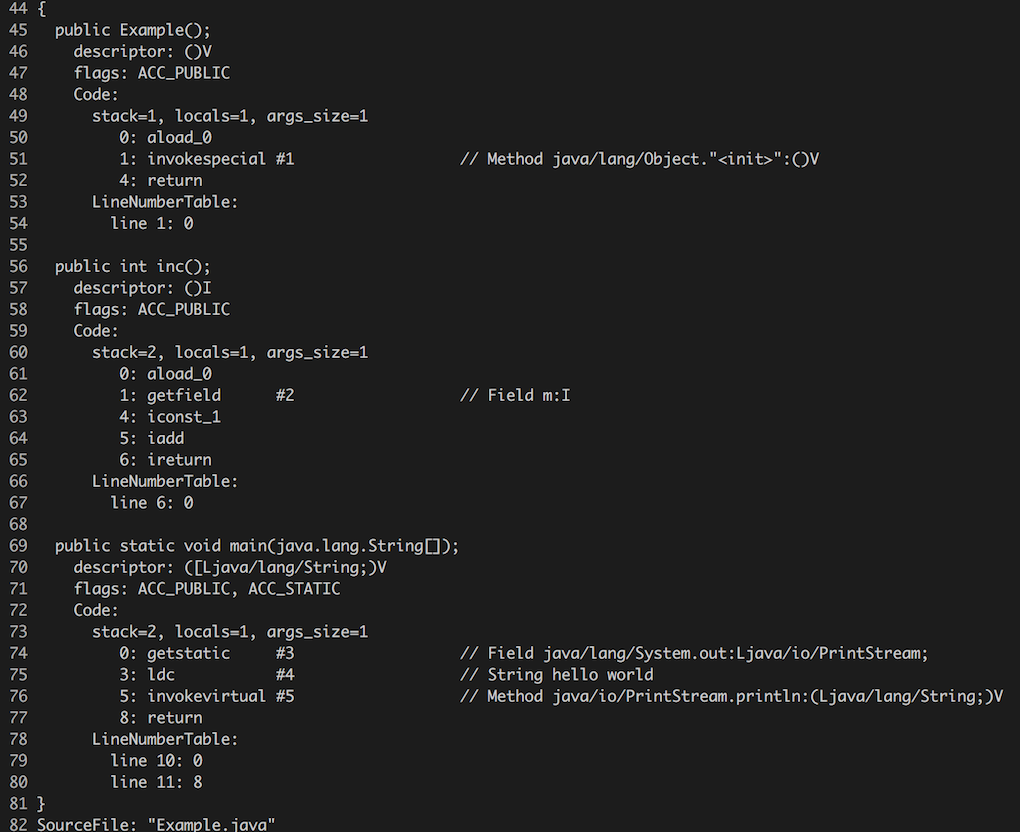
我们的例子中,使用 javap 命令后,能够得到一个好看的方法表集合。
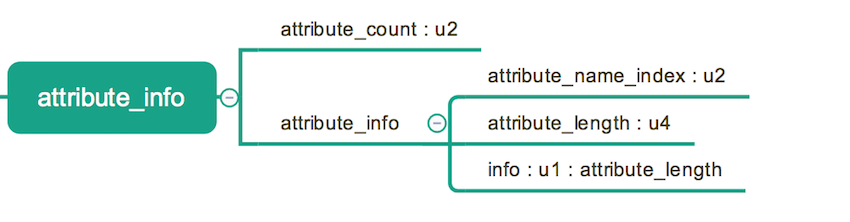
属性表,这个词在前面已经出现过挺多次的了。它可以出现在 Class 文件,字段表,方法表中,用来描述某些场景的专属信息。具体的表结构如下图所示。属性表与 Class文件中的其他数据项不太相同,它没有过于严格的顺序、长度和内容要求。任何人实现的编译器都可以向其中写入自己定义的信息, Java 虚拟机会忽略自己不认识的属性。当然,虚拟机预先定义了一些属性 (准确地说是 23 项)。由于这部分比较复杂,无法逐一详细解释,具体可以参考 JVM Specification (这里给出的链接是 Java SE 8 Edition)
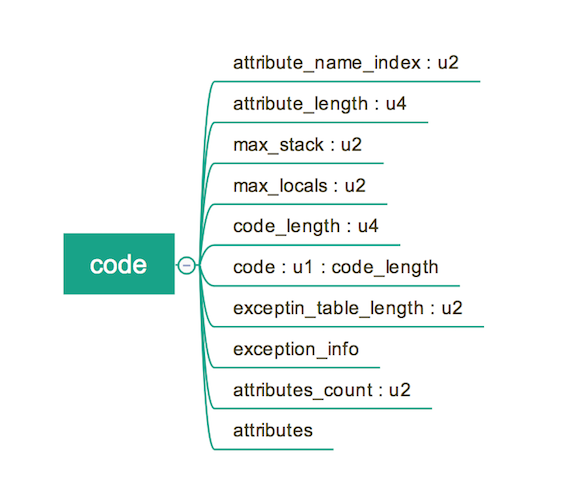
本节主要探讨该表中的 code属性,该属性位于上图的 info 中,是其中的一个子项(entry)。这个表存放的是某个方法的对应字节指令吗。其结构如下:
回忆一下我们是怎么把一个 .java 文件变成一个 .class 文件的。没错,那就是 javac 命令!我们知道,一个程序基本上可以分成两大部分,数据和操作数据的语句。当我们下这个命令的时候,所有的执行语句都被变成了字节码指令,被存放在了相应方法表的属性表中。除了 code 属性里的内容,其他的就都是程序的数据了。
让我们看看 code 表里究竟是个什么样子。
attribute_name_index,指向一个字面量 “Code”;attribute_length,指示了 code 属性值的长度。max_stack,代表了操作数栈的最大深度,虚拟机需要根据这个值分配栈帧中的操作栈深度。这里需要稍微展开一下,JVM 可以基于操作数栈,也可以基于寄存器。“Java HotSpot(TM)” 是基于操作数栈的, “Dalvik” (Andorid 上运行的 JVM) 则是基于寄存器的;max_locals,代表了方法内部的局部变量表所需要的空间,单位是 Slot,Slot 是虚拟机内部为局部变量分配内存的最小单位。注意,并不是定义了多少个局部变量,这个值就是多少,Slot 是可重用的资源。除了 double, long占用 2 个 Slot 以外,其他的数据类型均占 1 个 Slot;code_length和 code用来存放指令的个数和具体指令。由于指令的数据类型是 u1,所以最多只能定义 256 条,目前已经定义了的指令有大约 200 条。本节不打算深入字节指令码,但是我们可以通过我们的例子,稍微的看看。在源码中,我们有如下的方法定义:
public int inc() {
return m + 1;
}
使用 javap 命令解析后,我们可以得到如下的指令:
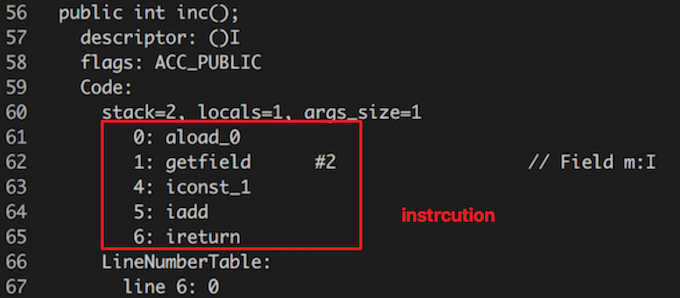
稍微解释一下上面的指令:
aload_0 -> 将第 0 个 Slot (this) 中为 reference 类型的本地变量推入操作数栈顶gefield #2 -> 取操作数栈顶的 reference 类型的变量,提取它的字段,字段信息由常量池中 index 为 2 的子项决定 (this.m)iconst_1 -> 将一个整形变量 1 推出操作数栈iadd -> 整形加入指令,操作数数量为 2,即操作数栈顶的两个元素 (this.m 和 1)ireturn -> 返回一个整形变量再多嘴一句,指令集的具体信息,可以在 JVM Specification 中第六章找到。属性表还有其他很多有用的信息,比如异常表等,但是不在这里逐一叙述了,有兴趣可以阅读上面的材料。
本文粗略介绍了 Class 文件的结构。往上,可以了解 javac 产出的结果;往下,可以帮助理解 JVM 的字节码执行引擎是如何工作的。
Apr 28, 2018 Montreal